Improving Patient Insights With Textual ETL in the Lakehouse Paradigm
By W H Inmon
This article is the result of a collaboration with our partner Databricks, the Data + AI company. A special thanks to Amir Kermany, Technical Director, Healthcare and Life Sciences at Databricks, and Michael Sanky Global Industry Lead, Healthcare & Life Sciences at Databricks.
The amount of healthcare data generated today is unprecedented and rapidly expanding with the growth in digital patient care. Yet much of the data remains unused after it is created. This is particularly true for the 80% of medical data that is unstructured in forms like text and images.
In a health system setting, unstructured provider notes offer an important trove of patient information. For example, provider notes can contain patient conditions that are not otherwise coded in structured data, patient symptoms that can be signals of deteriorating status and disease, and patient social and behavioral history.
Every time a patient undergoes care, providers document the intricacies of that encounter. The amount of raw text and the nature of the language depends on the provider and many other factors. This creates a lot of variability in what text is captured and how it is presented. The collection of these raw text records serves as the basis for a patient’s medical history and provides immense value to both the individual patient and entire populations of patients. When records are examined collectively across millions of patients, researchers can identify patterns relating to the cause and progression of the disease and medical conditions. This information is critical to delivering better patient outcomes.
Raw unstructured text data, such as provider notes, also contains very important information for patient care and medical research; however, textual data is usually filed away and goes untapped due to the complexity and time required to manually review it. Extracting information from textual provider notes, and combining it with more traditional structured data variables, offers the most complete view of the patient as possible. This is critical for everything from advancing clinical knowledge at the point of care and supporting chronic condition management to delivering acute patient interventions.
Challenges analyzing healthcare textual data
The challenge for health systems in making use of these data sets is that traditional data warehouses, which typically utilize relational databases, do not support semi-structured or unstructured data types. Standard technology handles structured data, numerical data and transactions quite well; however, when it comes to text, it fails at retrieving and analyzing the text. The lack of structure of the text defeats many of the advantages provided by the data warehouse.
A second reason why legacy data architectures do not lend themselves to the collective analysis of patient data is that most of the data resides on very different sources and proprietary technologies. These technologies simply were never designed to work seamlessly with other technologies, and often prohibit analysis of unstructured text at scale.
Furthermore, these legacy systems were never designed for big data, advanced analytical processing or machine learning. Built for SQL-based analytics these systems are suitable for reporting on events in the past, but do little in the way of providing predictions into the future which is critical to delivering on innovative new use cases.
Unlocking patient insights with Forest Rim Technology and Databricks Lakehouse Platform
Forest Rim Technology, the creators of Textual ETL, and Databricks can help healthcare organizations overcome the challenges faced by legacy data warehouses and proprietary data technologies. The path forward begins with the Databricks Lakehouse, a modern data platform that combines the best elements of a data warehouse with the low-cost, flexibility and scale of a cloud data lake. This new, simplified architecture enables health systems to bring together all their data — structured (e.g. diagnoses and procedure codes found in EMRs), semi-structured (e.g. organized textual notes), and unstructured (e.g. image or textual data) — into a single, high-performance platform for both traditional analytics and data science.
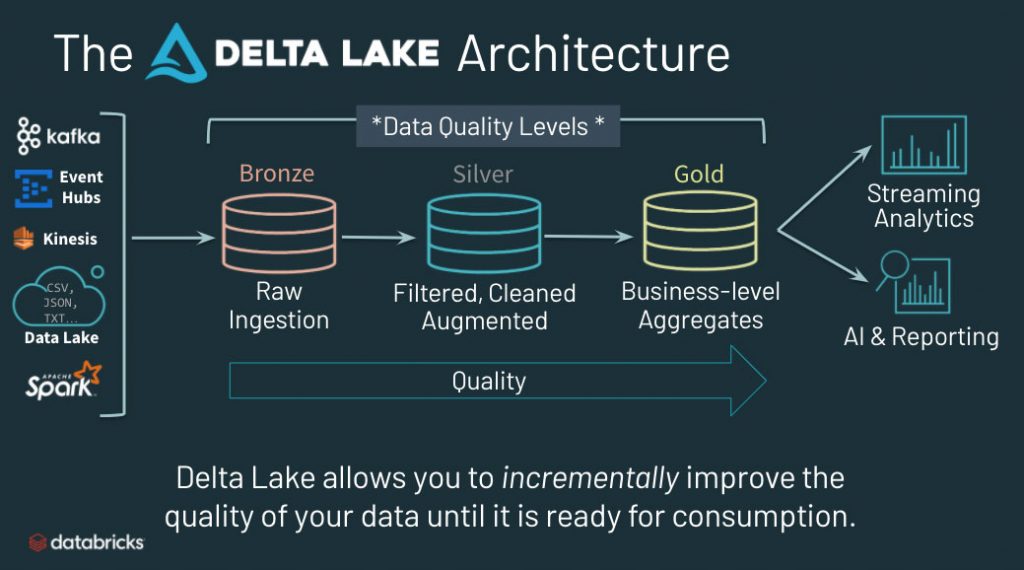
At the core of the Databricks Lakehouse platform is Delta Lake, an open-source storage layer that brings reliability and performance to data lakes. Healthcare organizations can land all of their data, including raw provider notes, into the Bronze ingestion layer of Delta Lake (pictured below). This preserves the original source of truth before applying any data transformations. By contrast, with a traditional data warehouse, transformations occur prior to loading the data. As such, all structured variables extracted from unstructured text are disconnected from the native text. The lakehouse architecture also provides a full suite of analytics and AI capabilities so organizations can begin exploring their data without replicating into another system.
Forest Rim Technology builds on Databricks’ capabilities with Textual ETL, an advanced technology that reads raw, narrative text, such as that found in medical records, and refines that text into structured data that can easily be ingested into Delta Lake. Textual ETL is capable of converting unstructured medical notes that come from any electronically readable source into a structured format. Other capabilities of Textual ETL include homographic resolution and translating textual data in different languages. Currently Textual ETL supports many languages including English, Spanish, Portuguese, German, French, Italian and Dutch. Unstructured textual data can be processed into structured data securely, ensuring that any sensitive data is protected and governed. The combination of Databricks Lakehouse Platform and Textual ETL makes it possible to analyze data for a patient, a group of patients, an entire hospital or an entire country.
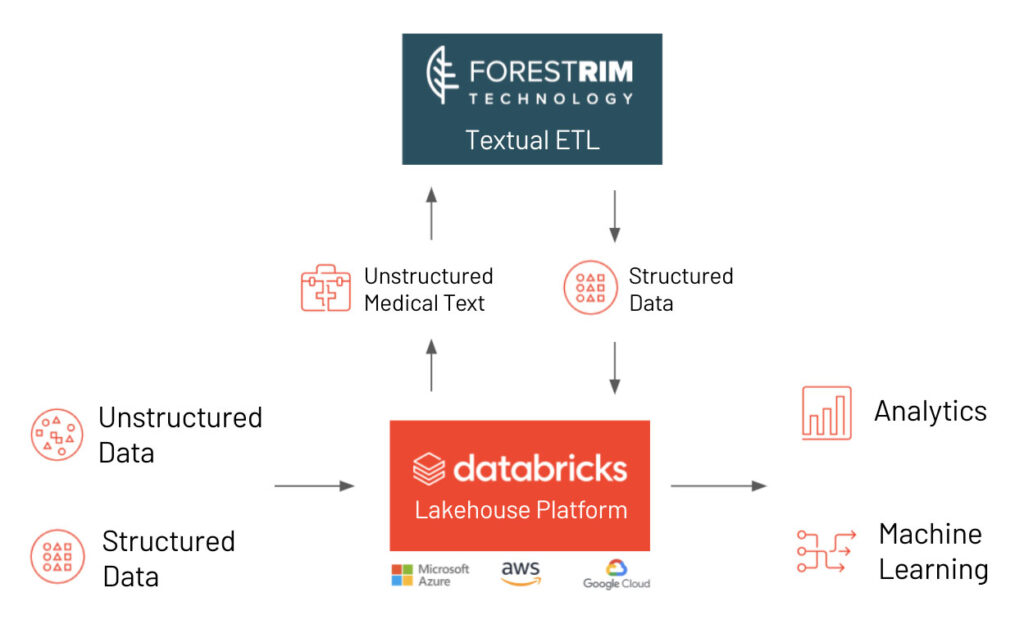
Analyzing medical records at scale with Textual ETL and Databricks Lakehouse
To demonstrate the power of Textual ETL in the Lakehouse architecture, Forest Rim and Databricks generated a large number of textual synthetic medical records using Synthea, the Synthetic Patient Population Simulator. The electronic textual medical records ranged in size, from 10 pages in length for a patient to more than 40 pages.
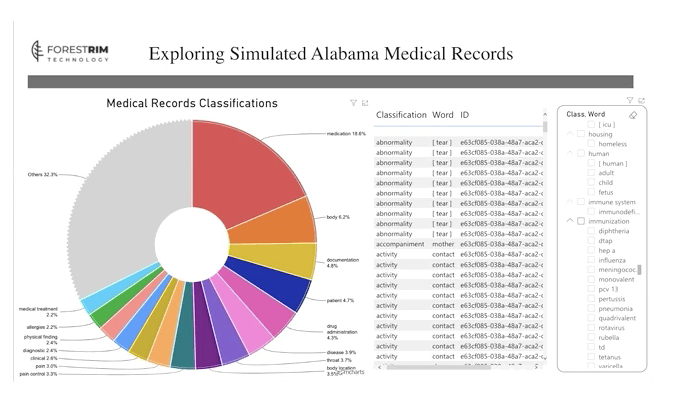
Textual ETL uses sophisticated ontologies and can disambiguate differences in medical terminology (for example, the abbreviation “HA” to a cardiologist means “heart attack” while the same abbreviation to other providers could mean “headache” or “Hepatitis A”). In this example, Forest Rim Technology deployed Textual ETL to identify and extract values from the text ranging from demographic (age, gender, geography and race) to medical (symptoms, conditions and medications). The resulting variables were then used as the input to a visualization tool to begin to explore the data. Databricks’ Lakehouse enables integration with business intelligence (BI) tools directly from Delta Lake to facilitate fast exploration and visualization of relationships in the data.
For this example, we focused on simulated records from the state of Alabama and could easily explore all the textual notes after processing the data using Textual ETL and connecting the structured results to Microsoft PowerBI. This enabled us to explore the data and understand the most frequently discussed topics between providers and patients, as well as specific distributions like immunizations.
Textual ETL and Databricks’ Lakehouse facilitates detailed drill downs, and we can easily explore correlations across domains such as medications and diseases by different parameters such as gender, age, geography and marital status, as seen in the GIF below.
Once the electronic textual medical records have been processed by Textual ETL, researchers, analysts and data scientists can support everything from reporting through machine learning use cases or other advanced analytical tools. An additional advantage of Lakehouse is that the original notes reside in Delta Lake, enabling users to easily review the full patient record as needed (compared to data warehouses, where the full notes likely reside in a separate system). Furthermore, the notes data can be linked to data from the structured record to reduce time for the clinician and improve overall patient care.
Databricks and Forest Rim Technology bring a shared vision to provide a trusted environment in which sensitive, unstructured healthcare data can be securely processed in Lakehouse for analytical research. As healthcare data continues to grow, this vision provides a trusted environment for deeper insights through Textual ETL while protecting the sensitive nature of healthcare information.
About Forest Rim Technology: Forest Rim Technology was founded by Bill Inmon and is the world leader in converting textual unstructured data to a structured database for deeper insights and meaningful decisions. The Forest Rim Medical Data mission is to enable governments and health institutions to use textual information for analytical research and patient care at a lower cost